 SLIDE (1,089KB)
SLIDE (1,089KB)(上の「SLIDE」をクリックするとスライドを表示します。 ナレーションも入っていますので、スピーカーの電源を入れて下さい。 但し、 Microsoft PowerPoint が必要です。 )
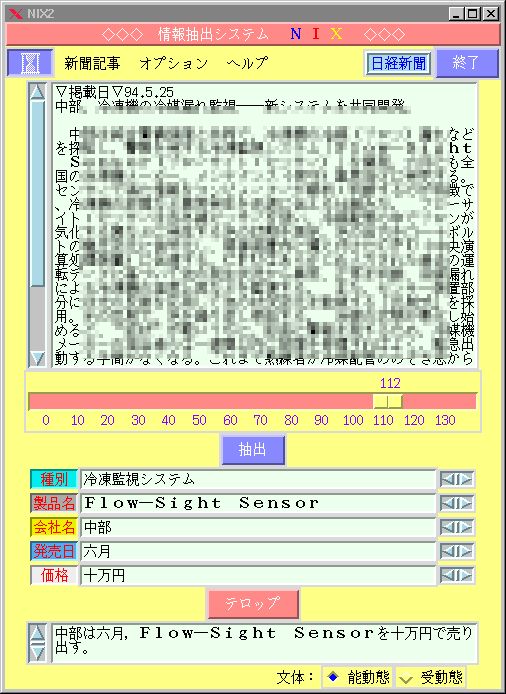
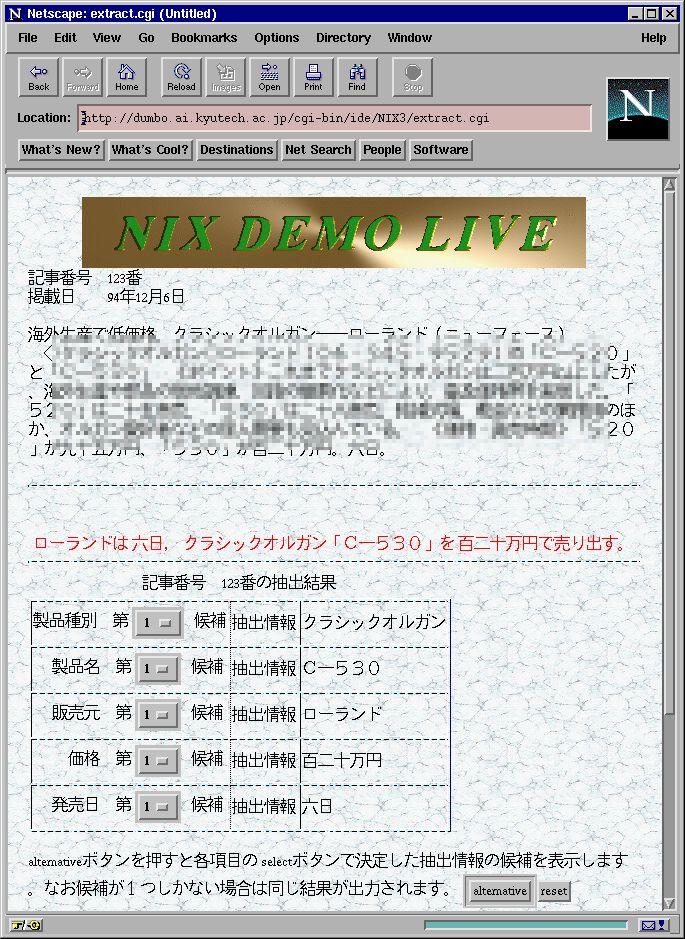
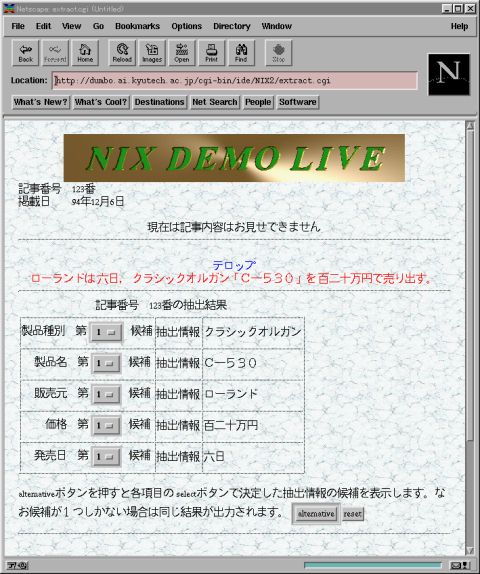
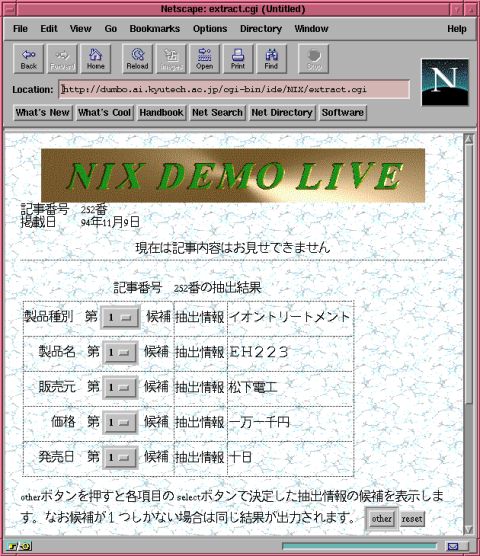
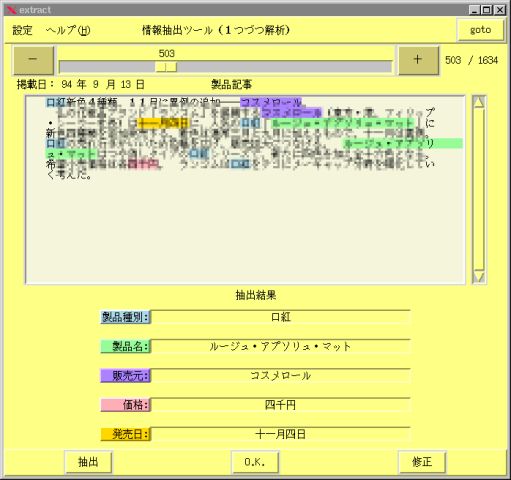
現在は、新製品に関する新聞記事から情報を抽出する情報抽出システムNIX(News Items Extractor)の研究を進めています。下の図はNIXシステムのディスプレイのコピーです。このWebには実際に動かしてみることができる がありますので、試してみて下さい。
同じエンジンを搭載したスタンドアロンシステムとWebシステムの二種類のシステムがあります。さらに、異なる処理方式の二種類のエンジンがあります。
抽出する情報の項目は、 製品種別、 製品名、 販売元、 価格、 発売日 の五つです。この中で、製品種別の言語表現にはいろいろな形と内容のものがあるため処理がたいへんむずかしく、抽出精度は約 80% です。他の四つの項目、すなわち製品名、販売元、価格、発売日の言語表現には定型性があるため処理が比較的うまくいき、抽出精度は、約 93% です。
一般に、一つのニュース記事には、 複数の製品 が紹介されています。 機能等が違う製品シリーズです。このような紹介記事には多くの並列 表現が含まれています。したがって、新しいバージョンのものは抽出する情報の項目を一つ増やし、 製品細分類を加えて六項目にしています。 さらに、 製品の特徴 などについて書かれている部分もあります。したがって、 最新のバージョンのものは、これらの特徴も抽出します。
本研究では、「日本経済新聞 CD-ROM 90,91,92,93,94,95 版」および「毎日新聞 CD−ROM 90,91,92,93,94,95 版」に収録されている記事を許可を受けて使用しています。
|
SLIDE (1,089KB) (上の「SLIDE」をクリックするとスライドを表示します。 ナレーションも入っていますので、スピーカーの電源を入れて下さい。 但し、 Microsoft PowerPoint が必要です。 ) |
 |
 |
 |
 |
 |
 |
| NIX V.3 | NIX V.2b | NIX V.2a | NIX V.1b | NIX V.1b | NIX V.1a |
 ホームページへもどる
ホームページへもどる